
<잇(IT)터뷰 전체 영상 보기>
잇(IT)터뷰 전체 내용은 ▼아래 영상▼에서 확인해 주세요!
◼ 게스트 : 김선영 그룹장 / 엔코아
◼ 진행자 : 고우성 PD / 토크아이티 (wsko@talkit.tv, https://talkit.tv/)
영상 목차
◼ 아래 각 목차를 클릭하시면 해당 내용을 영상으로 바로 보실 수 있습니다.
✔ 기업 AI 프로젝트의 높은 실패율
✔ AI-Ready Data의 정의
✔ 데이터 준비의 3대 병목
✔ Meta# AI 솔루션
✔ 글로벌 오디오 제조사 사례
<잇(IT)터뷰 – 핵심 내용 파악하기>
‘잇(IT)터뷰 – 핵심 내용 파악하기’는 영상의 핵심 내용을 정리한 글입니다.
|
이번 잇(IT)터뷰는 기업 AI 프로젝트의 높은 실패율 원인과 해결책을 다룹니다. MIT와 Gartner 조사에 따르면 대부분의 AI 프로젝트가 ROI를 창출하지 못하는 주요 원인은 데이터 거버넌스 부족입니다.
AI-Ready Data의 개념을 정의하고, 레거시 시스템의 메타데이터 부재, 비표준 정의, 모델 불일치 등 데이터 준비의 3대 병목을 설명합니다. 엔코아의 Meta# AI 솔루션이 생성형 AI와 27년 컨설팅 노하우를 결합하여 4-12개월 걸리던 데이터 표준화 작업을 어떻게 3시간으로 단축하는지 실제 사례로 증명합니다.
1. 기업 AI 프로젝트의 높은 실패율
MIT 보고서에 따르면 기업 AI 배포의 95%가 가치를 창출하지 못한다. Gartner는 2027년까지 기업의 60%가 데이터 거버넌스 부족으로 AI 가치 실현에 실패할 것으로 전망한다.
실패의 핵심 원인은 “GenAI Divide” – AI 기술은 빠르게 발전하지만 기업의 데이터 준비 수준은 따라가지 못하는 격차다.
많은 기업이 화려한 AI 애플리케이션 구축에만 집중하고 데이터 기반을 간과한다. “데이터가 준비되지 않으면 RAG는 환각(hallucination)을 일으킨다”는 말처럼, 아무리 뛰어난 AI 모델도 품질 낮은 데이터로는 제대로 작동할 수 없다.
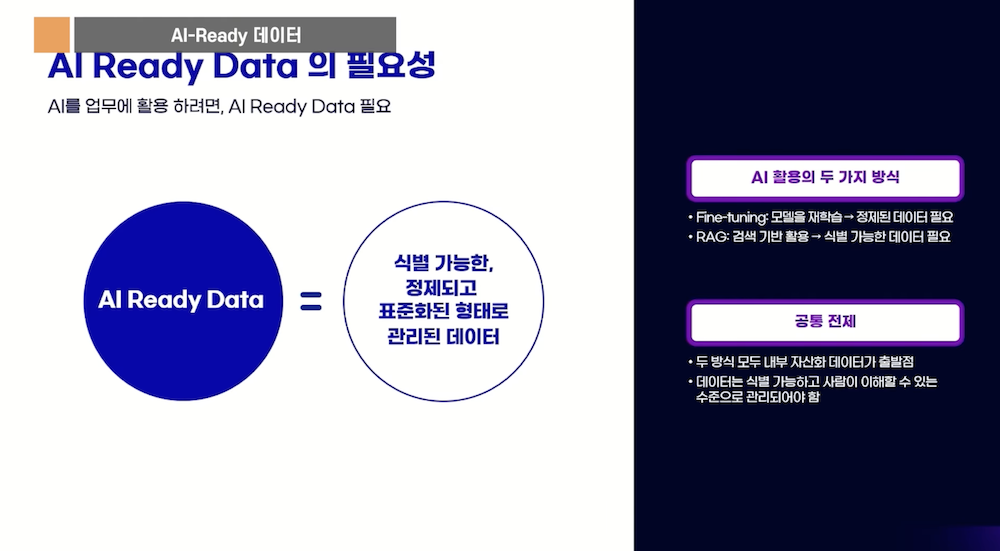
2. AI-Ready Data의 정의와 중요성
AI-Ready Data란 AI가 효과적으로 활용할 수 있도록 식별 가능하고, 정제되고, 표준화된 데이터를 의미한다.
*핵심 요소
– 식별 가능성: 각 데이터 항목이 무엇을 의미하는지 명확히 정의
– 정제: 중복, 오류, 불일치 제거
– 표준화: 일관된 형식과 용어 사용
레거시 시스템의 데이터는 대부분 이러한 조건을 충족하지 못한다. 수십 년 전에 만들어진 데이터베이스는 문서화가 부실하거나 아예 없으며, 개발자만 이해할 수 있는 암호 같은 테이블명과 컬럼명으로 가득하다.
3. 데이터 준비의 3대 병목
엔코아의 김선영 그룹장은 데이터를 AI-Ready 상태로 만드는 과정에서 마주치는 세 가지 주요 병목을 설명했다.
1) 메타데이터 추출 및 표준화
오래된 시스템은 문서가 없거나 분실되었다. AIS_ABC_GRTRM 같은 테이블명이 무엇을 의미하는지 아는 사람이 없다.
2) 비표준 정의
동의어와 동음이의어 문제. 같은 개념을 다른 부서가 다른 이름으로 부르거나, 같은 이름이 다른 의미로 사용된다.
3) 모델 동기화
현재 DB 스키마와 오래된 문서 간의 불일치. 시스템은 계속 변경되었지만 문서는 업데이트되지 않았다.
전통적 해결 방법의 한계를 보면, 수작업 데이터 표준화는 22단계의 복잡한 프로세스로 4-12개월이 소요된다. AI 붐이 일어나는 현재, 이러한 속도로는 경쟁에서 뒤처질 수밖에 없다.
4. Meta# AI – AI로 데이터 거버넌스 해결
엔코아의 Meta# AI(메타샵 AI) 솔루션은 생성형 AI를 활용하여 데이터 거버넌스의 “콜드 스타트” 문제를 해결한다.

1) 핵심 접근법
단순히 LLM에 데이터를 던지는 것이 아니라, 27년의 데이터 컨설팅 노하우를 결합한다. 제조업, 금융, 유통 등 도메인별 비즈니스 로직을 프롬프트에 반영하여 정확도를 높인다.
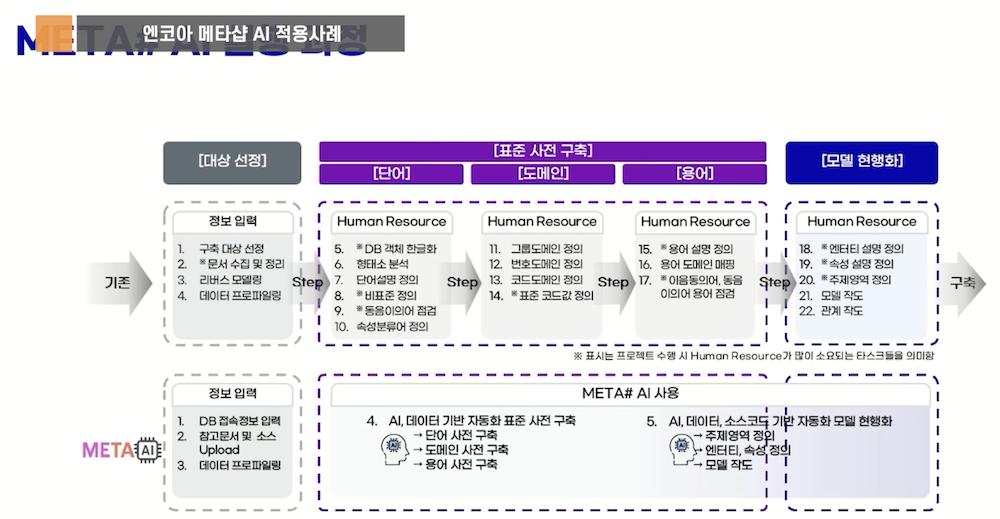
2) 프로세스 혁신
– 기존 방식: 22단계, 4-12개월
– Meta# AI: 5단계, 수시간
3) 작동 방식
– 암호화된 DB 스키마 입력
– AI가 비즈니스 로직 역공학(Reverse Engineering)
– 엔티티명, 기능 정의, 데이터 생성 규칙 자동 생성
– 도메인과 데이터 타입 추론
– 표준화된 메타데이터 출력
특히 AI는 컨텍스트를 기반으로 데이터 타입까지 추론한다. 예를 들어 VARCHAR(8) 컬럼이 날짜 형식임을 주변 컨텍스트로 판단한다.
5. 글로벌 오디오 제조사 실제 사례
1) 고객 상황
글로벌 오디오 제조사가 단일 파일에 191개 컬럼을 가진 테이블을 보유했으나 문서가 거의 없었다. 테이블명은 AIS_ABC_GRTRM 같은 암호 수준이었다.
2) 처리 과정
Meta# AI가 단 3시간 만에 처리를 완료했다.
3) 출력 결과
– 엔티티명: “출장 그룹 관리”로 추론
– 기능 정의: 명확한 업무 설명 생성
– 데이터 생성 규칙: 각 컬럼의 생성 로직 문서화
– 도메인/데이터 타입: 정확한 타입 분류

4) 고객 반응
“이것이 우리(내부 전문가)가 한 것보다 낫다”는 평가를 받았다. 내부적으로 수개월간 시도했던 작업을 AI가 몇 시간 만에 더 높은 품질로 완성했다.
5) 경쟁 우위의 비밀
단순한 AI 기술이 아니라 AI + 도메인 지식의 결합이다. 제조업 로직, 금융 규제, 유통 프로세스 등 업종별 컨설팅 경험이 프롬프트에 녹아들어 정확도를 높인다.
6) 결론: AI 시대의 데이터 전략
AI 애플리케이션 구축에 앞서 데이터 기반부터 제대로 다져야 한다. 수작업 데이터 거버넌스는 AI 시대의 속도를 따라갈 수 없다.
7) 핵심 교훈
– 데이터 우선: 화려한 AI 포털보다 데이터 품질이 먼저
– AI로 AI 준비: 데이터 거버넌스 문제도 AI로 해결
– 도메인 지식 필수: 순수 LLM만으로는 부족, 업종 전문성 결합 필요
Meta# AI 같은 솔루션은 4-12개월 걸리던 작업을 수시간으로 단축하여 기업이 AI 경쟁에서 뒤처지지 않도록 돕는다. AI-Ready Data 확보가 곧 AI 프로젝트 성공의 열쇠다.
◼ 전체 잇(IT)터뷰 내용은 ▶영상으로 바로 가기(클릭)◀에서 확인하실 수 있습니다.
|
◼ 콘텐츠 & 웨비나 문의 : marketing@talkit.tv, 02-565-0012
Copyright ⓒ 토크아이티 All rights reserved. 무단 전재 및 재배포 금지.