
<잇(IT)터뷰 전체 영상 보기>
잇(IT)터뷰 전체 내용은 ▼아래 영상▼에서 확인해 주세요!
◼ 게스트 : 이석중 대표 / 라온피플 (mdcho@laonpeople.com)
◼ 진행자 : 고우성 PD / 토크아이티 (talkit@talkit.tv, https://talkit.tv/)
<잇(IT)터뷰 – 핵심 내용 파악하기>
‘잇(IT)터뷰 – 핵심 내용 파악하기’는 영상의 핵심 내용을 정리한 글입니다.
|
이번 잇(IT)터뷰는 VLM(Vision-Language Model) 기반 관제/피지컬 AI에서 핵심 병목이 “비디오의 시간 맥락”과 “롱 컨텍스트(토큰 폭증)”이며, 이를 트랜스포머 구조만으로 처리할 때 연산·메모리 비용이 급격히 커진다는 문제를 정리합니다.
그리고 이 병목을 줄이기 위한 방향으로 트랜스포머의 비용(어텐션) 구조를 설명하고, Mamba 계열(SSM)의 “선택적 메모리” 관점이 VLM 경량화와 장시간 맥락 처리에서 왜 주목받는지 연결합니다.

1. VLM 관제에서 “한 장면”만 보면 오판한다: 시간 맥락이 정답을 만든다
예를 들어 사람이 가방을 만지는 장면만 보면 “가방을 놓는지, 드는지”를 구분하기 어렵다. 사람이 다가와 가방을 놓고 사라지는 흐름(전후 상황)을 봐야 “가방을 두고 갔다”라는 의미가 확정된다. 결국 관제는 프레임 단위 정지 화면 이해를 넘어, 시간적 의미(temporal context)를 이해해야 맥락이 깨지지 않는다.
2. 입력 단계 병목: 프레임 폭증은 곧 토큰 폭증이고 비용 폭증이다
비디오를 시간 맥락으로 이해하려면 입력 데이터가 폭발한다. 1초 60fps라면 1분에 3,600장이 된다. 어떤 상황은 5분 전, 어떤 상황은 1시간 전 영상과의 관계까지 따져야 할 수도 있다. 이때 “그 긴 구간을 그대로 다 넣는 방식”은 현실적으로 컨텍스트 한계를 넘어간다.
그래서 입력 단계에서 다음 같은 전략이 필요하다고 정리한다.
중요 장면이 없을 때는 일정 간격으로 샘플링해서 본다.
변화가 많아 “이벤트가 일어날 가능성”이 크면 그 구간에 자원을 더 집중한다.
비슷한 장면/토큰은 머지(merge)해서 토큰 처리 비용을 줄인다.
3. 모델 단계 병목: 스태틱 VLM을 “비디오용으로 통째로 재학습”하면 비용이 너무 크다
일반적인 VLM은 기본적으로 “한 장면(정지 화면)” 이해에 맞춰져 있다. 이를 비디오 프레임 이해로 바꾸려면 재학습/재구성이 필요해 비용이 커진다.
그래서 실무적으로는 다음 접근이 소개된다.
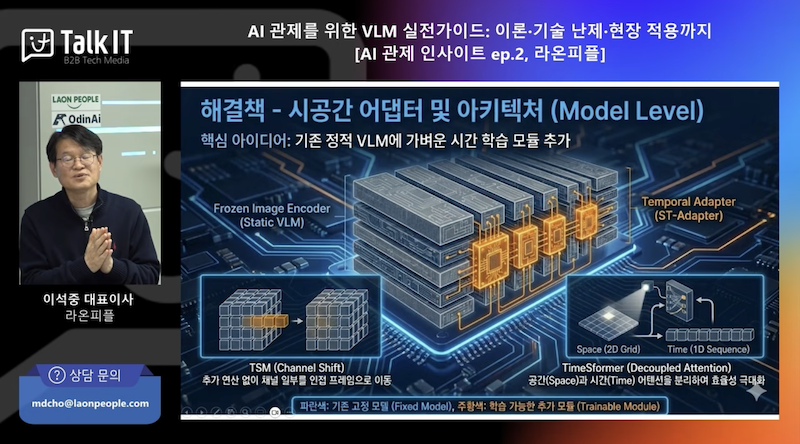
학습이 끝난 스태틱 VLM은 프리즈닝(고정)한다.
시간 맥락을 해석할 수 있도록 템퍼럴 어댑터(temporal adapter)를 붙인다.
4. 트랜스포머의 근본 비용: 어텐션은 토큰이 늘수록 “제곱”으로 커진다
트랜스포머는 어텐션(attention)으로 “들어오는 모든 토큰 간 관계”를 계산한다.
토큰 수가 늘어나면 계산량이 L의 제곱에 비례해 커진다.
비디오는 프레임도 많고, 프레임 하나에서도 토큰이 많이 나오므로 트랜스포머 기본 방식으로는 비용이 기하급수적으로 커질 수밖에 없다. 그래서 트랜스포머 진영에서도 비용을 제곱이 아니라 선형에 가깝게 줄이려는 연구(예: Flash Attention 등)가 계속 나온다고 정리한다.
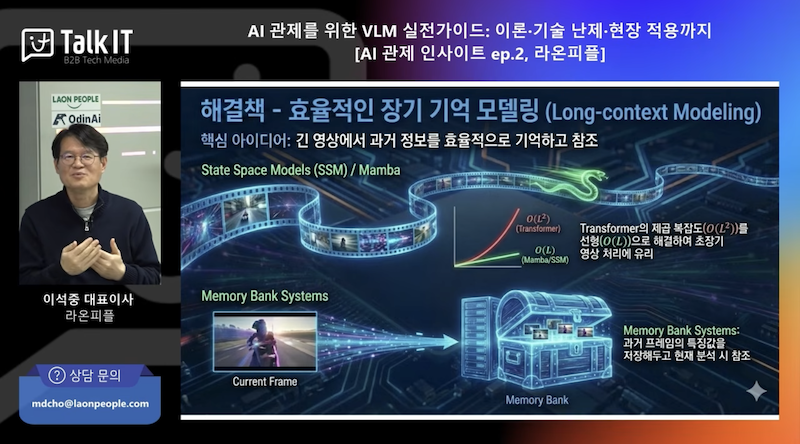
5. MAMBA(SSM) 핵심: 선택적 메모리로 “중요한 토큰만 본다”
MAMBA는 트랜스포머와 결이 다른 SSM(State Space Model) 계열로 소개된다. 핵심은 “선택적 메모리”다. 사람도 중요하지 않은 배경은 스킵하고 핵심만 보듯, MAMBA는 의미 없는 토큰은 대체로 넘기고 중요한 정보에 집중한다.
영상의 비유는 이렇게 정리된다.
– 트랜스포머: 시험공부할 때 책 전체를 다 보는 방식
– MAMBA: 요약 노트(핵심)만 보는 방식
이 관점이 롱 컨텍스트를 다루는 비디오/VLM에서 매력적으로 보인다는 결론으로 이어진다.
6. “서프라이즈”를 중심으로 중요도를 잡는다: 변화/예측불가가 핵심 토큰이 된다
MAMBA 관점에서 중요한 신호는 “서프라이즈(surprise)”다.
앞에서 A가 나오면 다음이 B로 자연스럽게 예측되는 경우는 서프라이즈가 낮고, 예상과 다르게 튀는 변화가 나오면 서프라이즈가 커진다. 이런 변화가 큰 상태(state)를 더 중요하게 본다는 설명이다.
또한 “세세한 기억”은 트랜스포머가 유리할 수 있지만, 전체 맥락(큰 흐름) 이해 관점에서는 MAMBA가 더 맞을 수 있다는 비교가 나온다.
7. 결론: 비디오 VLM에서는 장시간 컨텍스트와 메모리 관리가 핵심 과제다
비디오로 갈수록 토큰이 폭증하고, 트랜스포머는 비용 구조상 부담이 커진다. 그래서 “제곱이 아니라 선형적으로 증가하는 처리”, “중요한 토큰 선별”, “메모리 관리”가 중요해지고, 이 맥락에서 MAMBA 계열을 앞으로 더 봐야 한다는 관점을 제시한다.
8. 3줄 요약 (핵심만)
– VLM 관제는 정지 화면 이해를 넘어 시간 맥락을 이해해야 하고, 비디오는 프레임/토큰 폭증으로 비용이 급격히 커진다.
– 트랜스포머는 어텐션 때문에 토큰이 늘수록 비용이 제곱으로 증가해 롱 컨텍스트에 불리하며, 이를 줄이려는 연구가 진행 중이다.
– MAMBA(SSM)는 선택적 메모리로 중요한 토큰(서프라이즈/변화)을 중심으로 처리해 VLM 경량화와 장시간 맥락 처리에서 유망한 대안으로 제시된다.
◼ 전체 잇(IT)터뷰 내용은 ▶영상으로 바로 가기(클릭)◀에서 확인하실 수 있습니다. |
◼ 콘텐츠 & 웨비나 문의 : marketing@talkit.tv, 02-565-0012
Copyright ⓒ 토크아이티 All rights reserved. 무단 전재 및 재배포 금지.