
<잇(IT)터뷰 전체 영상 보기>
잇(IT)터뷰 전체 내용은 ▼아래 영상▼에서 확인해 주세요!
◼ 게스트 : 이석중 대표 / 라온피플 (mdcho@laonpeople.com)
◼ 진행자 : 고우성 PD / 토크아이티 (talkit@talkit.tv, https://talkit.tv/)
영상 목차
◼ 아래 각 목차를 클릭하시면 해당 내용을 영상으로 바로 보실 수 있습니다.
✔ VLM이란?
✔ VLM 동작 원리
✔ VLM 크기
✔ VLM 전문기업의 경쟁력
<잇(IT)터뷰 – 핵심 내용 파악하기>
‘잇(IT)터뷰 – 핵심 내용 파악하기’는 영상의 핵심 내용을 정리한 글입니다.
|
1. VLM이 주목받는 이유 – 전통적 AI vs VLM
1) 전통적 컴퓨터 비전
– 객체 탐지: “사람”, “차”, “사과” 라벨 부여
– 사전 학습된 카테고리만 인식 가능
– 맥락 이해 불가
2) VLM의 차별점
– 상황 설명: “누군가가 사과를 한 입 베어먹고 테이블에 놓았다”
– 자연어 질의 응답: “이 장면에서 위험한 요소는?”
– 학습하지 않은 상황도 언어적 조합으로 추론

2. Vision-Language Model의 정의
1) 핵심 개념
이미지/비디오와 텍스트를 공통 임베딩 공간에 매핑하여 두 모달리티를 연결하는 AI 모델
2) 구성 요소
– Image Encoder: 비전 트랜스포머(ViT)로 이미지를 패치 단위로 처리
– Text Encoder: 언어 모델로 텍스트를 벡터화
– Fusion Layer: 두 벡터를 통합하여 멀티모달 이해
3) 응용 분야
– 보안/모니터링: 이상 상황 자동 감지 및 설명
– 의료: 의료 영상 판독 및 리포트 생성
– 제조: 품질 검사 자동화
3. 대표 모델의 진화: CLIP → LLaVA
1) CLIP (OpenAI, 2021)
– 4억 개 이미지-텍스트 쌍으로 학습
– Contrastive Learning: 일치하는 쌍은 가까이, 불일치는 멀리 배치
– Zero-shot 분류 능력 획득
2) LLaVA (2023, 오픈소스)
– CLIP의 비전 인코더 + LLaMA 언어 모델
– Projection Layer: 시각 특징을 LLM 입력 공간으로 변환
– Instruction Following: “이 이미지에서 이상한 점을 설명해줘” 같은 지시 수행
3) Video-LLaMA
– 비디오 프레임 시퀀스 + 오디오 통합
– 시간적 맥락 이해 (예: 충돌 장면 전후 분석)
4. VLM 작동 원리: Contrastive Learning 원리
1) 학습 과정
– 이미지와 매칭되는 텍스트를 벡터 공간에서 가까이 배치
– 매칭되지 않는 쌍은 멀리 밀어냄
– 수백만 쌍의 학습으로 공통 표현 공간 형성
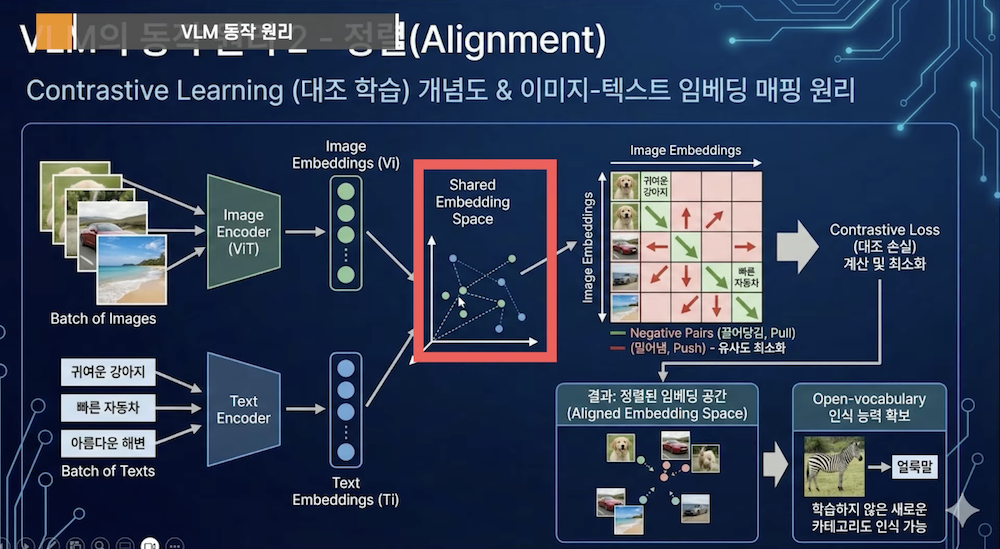
2) 예시
– “귀여운 강아지” (텍스트) ↔ 강아지 사진 (이미지) → 벡터 거리 최소화
– “귀여운 강아지” ↔ 고양이 사진 → 벡터 거리 최대화
5. Few-shot 학습과 조합적 추론 – 서핑 예시
1) 전통적 방식
서핑 장면 1만 장 학습 필요
2) VLM 방식
– “사람”, “서핑”, “높은 파도” 개념 개별 학습
– 조합적 추론: “높은 파도에서 서핑하는 사람” 자동 이해
– Few-shot: 새로운 개념도 소량 예시로 빠르게 적응
3) 실무 장점
– 희귀 상황(예: 공사장 특수 안전 사고) 학습 데이터 부족해도 대응
– 도메인 특화 파인튜닝으로 일반 모델 대비 높은 정확도
6. 효율성: 파라미터 규모와 GPU 요구사항
1) 파라미터 비교
– 대형 LLM: 100B+ 파라미터
– 모니터링용 VLM: 7B~10B 파라미터로 충분
2) 하드웨어 전략
– H100 같은 최고급 GPU 불필요
– RTX 4090 수준으로 실시간 추론 가능
– 도메인 특화 파인튜닝으로 효율 극대화
3) 최적화 기법
– Instruction Tuning: 특정 지시(예: “안전모 미착용 감지”) 최적화
– 경량화: Pruning, Quantization으로 모델 크기 축소
– On-premise 배포: 클라우드 비용 없이 독립 운영
4) 비용 효율성
– 70B 범용 모델 < 10B 파인튜닝 모델 (특정 도메인에서)
– 현장 맞춤형 데이터로 학습 시 성능 우위
7. 결론: VLM 도입의 3대 핵심
1) 맥락 이해가 게임 체인저
단순 탐지가 아닌 상황 설명 능력이 실무 가치 창출
2) Few-shot + 파인튜닝 전략
도메인 특화 데이터로 빠르게 최적화
3) 적정 규모 선택
7B~10B 모델로 비용과 성능 균형
4) 라온피플의 접근/
모니터링 특화 VLM 개발로 공사장, 제조 현장, 보안 시설의 지능형 감시 구현
모니터링 특화 VLM 개발로 공사장, 제조 현장, 보안 시설의 지능형 감시 구현
◼ 전체 잇(IT)터뷰 내용은 ▶영상으로 바로 가기(클릭)◀에서 확인하실 수 있습니다.
|
◼ 콘텐츠 & 웨비나 문의 : marketing@talkit.tv, 02-565-0012
Copyright ⓒ 토크아이티 All rights reserved. 무단 전재 및 재배포 금지.