
<잇(IT)터뷰 전체 영상 보기>
잇(IT)터뷰 전체 내용은 ▼아래 영상▼에서 확인해 주세요!
◼ 게스트 : 윤성열 대표 / 드림플로우
◼ 진행자 : 고우성 PD / 토크아이티 (wsko@talkit.tv, https://talkit.tv/)
이번 잇(IT)터뷰는 기업들이 자체 프라이빗 AI 환경을 구축할 때 고려해야 할 핵심 기술인 오픈소스 기반 LLM 증류 모델 활용과 양자화 기법에 대해 심도 있게 설명합니다.
증류는 대형 모델의 성능을 소형 모델에 전이시켜 효율성을 높이는 방법이고, 양자화는 모델의 정밀도를 낮춰 메모리 사용량과 비용을 획기적으로 줄이는 기술입니다.
특히 4비트 양자화를 통해 고성능 LLM도 일반 GPU에서 실용적으로 운용할 수 있으며, 한국어 대응력, 모델 교체 유연성 등을 고려한 AI 인프라 전략이 중요하다고 강조합니다.
영상 목차
◼ 아래 각 목차를 클릭하시면 해당 내용을 영상으로 바로 보실 수 있습니다.
✔ 증류 모델
✔ 양자화
<잇(IT)터뷰 – 핵심 내용 파악하기>
‘잇(IT)터뷰 – 핵심 내용 파악하기’는 영상의 핵심 내용을 정리한 글입니다.
|
1. 오픈 소스 LLM과 증류 모델의 발전
– 최근 구글 젬마, 메타 라마 3.3, 딥시크 R1, 알리바바 Qwen 2.5 등 성능이 우수한 오픈 소스 LLM들이 공개되고 있다.
– 증류 모델은 큰 모델(교사 모델)의 지식을 작은 모델(학생 모델)로 전수하는 기술로, 모델의 크기를 줄이면서도 성능을 유지할 수 있다.
– 증류 모델 구현 시 학생 모델은 제로 베이스가 아닌 기존의 성능 좋은 베이스 모델을 사용하여 학습한다.
– 알리바바의 Qwen(1.5B~32B)과 메타의 라마(7B, 8B) 등이 증류 모델의 베이스 모델로 사용되며, 한국어 성능은 Qwen이 우수하다.
– 기업들은 워크로드에 최적화된 오픈 소스 증류 모델을 선택하고, 모델 교체가 용이한 환경을 구축하여 빠르게 변화하는 AI 기술에 대응해야 한다.
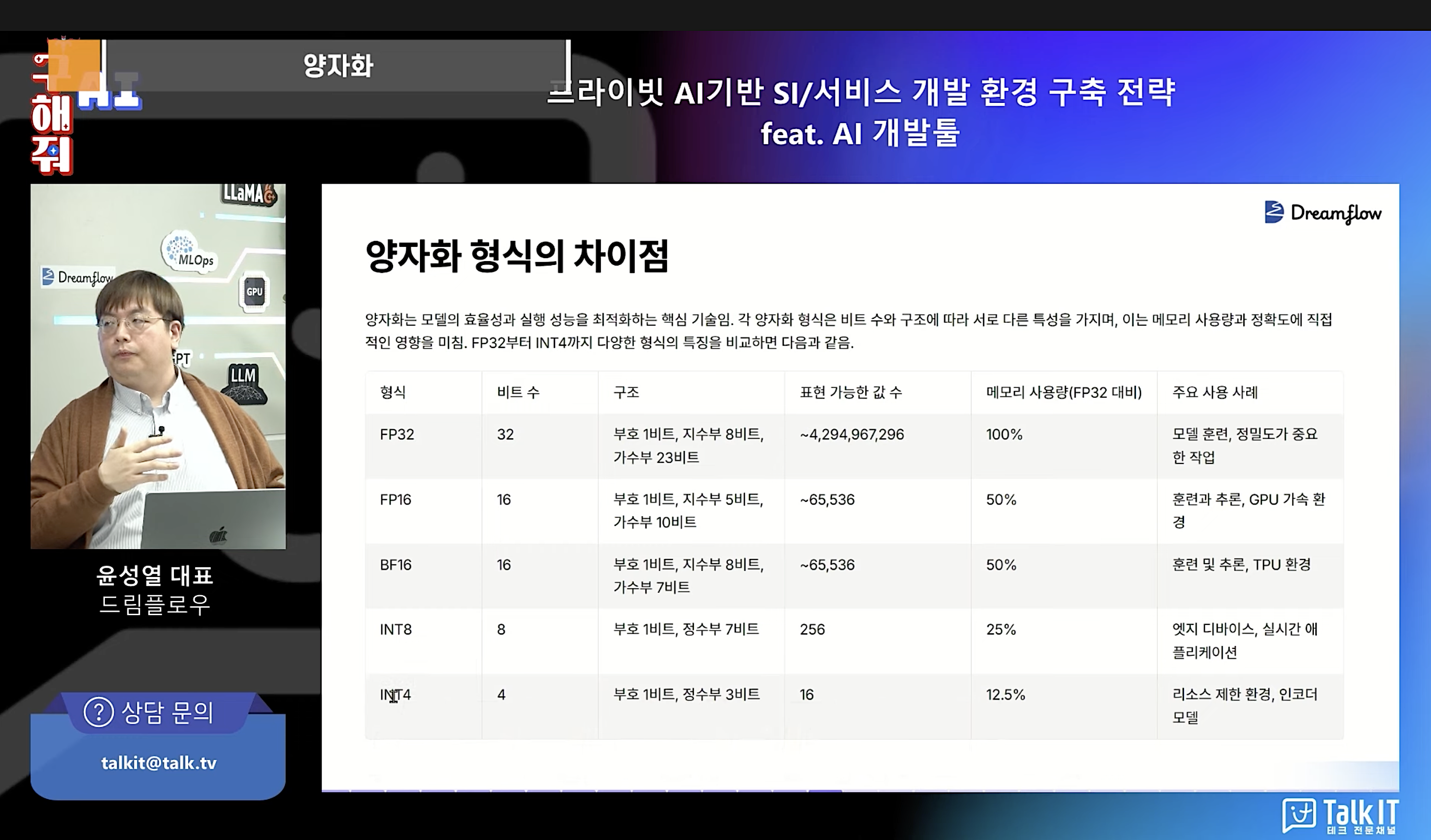
2. 양자화: LLM 경량화의 핵심 기술
– 양자화는 LLM의 매개변수 값을 근사값으로 반올림하여 모델의 크기를 줄이는 기술이다.
– LLM은 보통 32비트로 표현되는 매개변수를 가지고 있으며, 이는 모델의 전체 크기를 결정한다.
– 가장 많이 사용되는 양자화 형식은 4비트로, 이를 통해 메모리 사용량을 기존의 12.5%로 줄일 수 있다.
– 4비트 양자화는 대부분의 값을 정수 타입으로 변환하여 소수점 이하와 큰 숫자들을 제거하지만, 추론 시 충분한 성능을 보인다.
– 양자화를 통해 GPU 비용을 크게 절감할 수 있어, 기업의 프라이빗 AI 구현에 중요한 역할을 한다.
3. 양자화를 통한 GPU 메모리 사용량 최적화
– LLM 모델의 크기에 따라 필요한 GPU 메모리 용량이 크게 달라지며, 32B 모델은 양자화 없이 120GB의 메모리가 필요하다.
– 4비트 양자화를 적용하면 32B 모델은 15GB, 70B 모델은 32GB로 메모리 사용량이 크게 줄어 일반 그래픽카드로도 구동이 가능해진다.
– 8비트 기준으로 모델 크기(B)와 필요한 메모리 용량(GB)이 대략적으로 일치하며, INT4 양자화 시 이보다 약 절반으로 줄어든다.
– 600B 모델의 경우 INT8 양자화를 적용해도 600GB의 메모리가 필요해 현실적인 구동이 매우 어렵다.
– 양자화를 통해 GPU 비용을 크게 절감할 수 있지만, 모델 크기에 따라 적절한 양자화 방식을 선택해야 한다.
4. GPU 요구사항과 비용 절감 전략
– 32B 모델은 RTX 4090 한 장, 70B 모델은 두 장 이상의 GPU가 필요하다.
– 양자화 수준을 높이면 모델 품질은 향상되지만 하드웨어 비용이 크게 증가한다.
– 최근에는 극단적인 양자화(예: 1.5B까지)를 통해 성능을 유지하면서 비용을 절감하는 시도가 있다.
– 증류와 양자화의 적절한 균형을 찾는 것이 중요하며, 이는 워크로드와 적용 분야에 따라 다르다.
– 실제 사용 사례에 대한 지속적인 테스트가 필요하며, 한국어 모델의 경우 양자화 시 중국어가 섞이는 등의 문제가 있어 주의가 필요하다.
5. 양자화 기법과 LLM 서비스 구축
– GGML과 AWQ는 대표적인 양자화 기법으로, 각각 다른 특성을 가지고 있다.
– GGML은 범용적인 양자화 기법으로, GPU, CPU, ES 등 다양한 환경에서 추론이 가능하다.
– AWQ는 GPU에 최적화되어 있어, 본격적인 LLM 서비스 구축 시 적합하다.
– 양자화 기법 선택 시 하드웨어 환경과 서비스 목적을 고려해야 한다.
– LLM 기술 활용을 위해서는 지속적인 테스트와 검증이 필요하다.
◼ 전체 잇(IT)터뷰 내용은 ▶영상으로 바로 가기(클릭)◀에서 확인하실 수 있습니다.
|
◼ 콘텐츠 & 웨비나 문의 : marketing@talkit.tv, 02-565-0012
Copyright ⓒ 토크아이티 All rights reserved. 무단 전재 및 재배포 금지.